
Panel data sets in finance offer a powerful approach to understanding financial phenomena by combining cross-sectional and time-series dimensions. This structure provides significant advantages over purely cross-sectional or time-series analyses, allowing researchers to control for unobserved heterogeneity and examine dynamic relationships with greater precision. Essentially, a finance panel data set tracks multiple entities (firms, individuals, countries, portfolios, etc.) over a period of time. This results in a rectangular data structure where each row represents an observation for a specific entity at a specific point in time. Variables within the data set capture various financial metrics, such as stock returns, financial ratios, interest rates, macroeconomic indicators, and trading volumes. One of the key benefits of panel data is its ability to address endogeneity issues, particularly those stemming from omitted variable bias. By using fixed effects models, researchers can control for unobserved, time-invariant characteristics of each entity. These fixed effects capture any stable, unobserved differences between entities that might be correlated with the explanatory variables, thus reducing the risk of biased estimates. For example, when analyzing the impact of corporate governance on firm performance, a firm-specific fixed effect can account for inherent managerial quality or historical decisions that are difficult to quantify directly. Furthermore, panel data facilitates the investigation of dynamic relationships. Lagged values of variables can be included as explanatory variables, allowing researchers to explore how past performance or decisions affect current outcomes. Dynamic panel data models, such as those utilizing the Arellano-Bond estimator, are specifically designed to address the endogeneity issues that arise when lagged dependent variables are included. These models utilize internal instruments (lagged values of the variables) to control for past influences and potential reverse causality. The use of panel data is widespread across various areas of financial research. In corporate finance, it’s used to study capital structure decisions, investment behavior, and the impact of corporate governance on firm value. In asset pricing, it’s applied to examine the cross-sectional relationship between stock returns and various firm characteristics, such as size, book-to-market ratio, and momentum. In financial econometrics, panel data techniques are employed to develop and test models of market efficiency, volatility, and risk management. However, working with panel data requires careful consideration of potential econometric issues. Serial correlation within entities and heteroskedasticity across entities are common problems that need to be addressed using appropriate estimation techniques, such as clustered standard errors or generalized least squares (GLS). Additionally, researchers must choose the appropriate panel data model (fixed effects, random effects, or pooled OLS) based on the nature of the unobserved heterogeneity and the assumptions regarding its correlation with the explanatory variables. The Hausman test is often used to help guide this model selection. In conclusion, finance panel data sets provide a rich framework for analyzing financial phenomena, allowing researchers to control for unobserved heterogeneity, investigate dynamic relationships, and address endogeneity issues. By carefully applying appropriate econometric techniques, researchers can leverage the power of panel data to gain deeper insights into the complexities of financial markets and corporate behavior.
 512×442 household finance datasets dvara research from dvararesearch.com
512×442 household finance datasets dvara research from dvararesearch.com  1760×1140 finance data template excel google sheets templatenet from www.template.net
1760×1140 finance data template excel google sheets templatenet from www.template.net  626×351 premium photo financial data monitor finance data concept from www.freepik.com
626×351 premium photo financial data monitor finance data concept from www.freepik.com  580×689 summarized data set panel projects scientific diagram from www.researchgate.net
580×689 summarized data set panel projects scientific diagram from www.researchgate.net  1024×768 econometric analysis panel data powerpoint from www.slideserve.com
1024×768 econometric analysis panel data powerpoint from www.slideserve.com  1500×1101 financial data monitor finance data concept stock photo from www.shutterstock.com
1500×1101 financial data monitor finance data concept stock photo from www.shutterstock.com 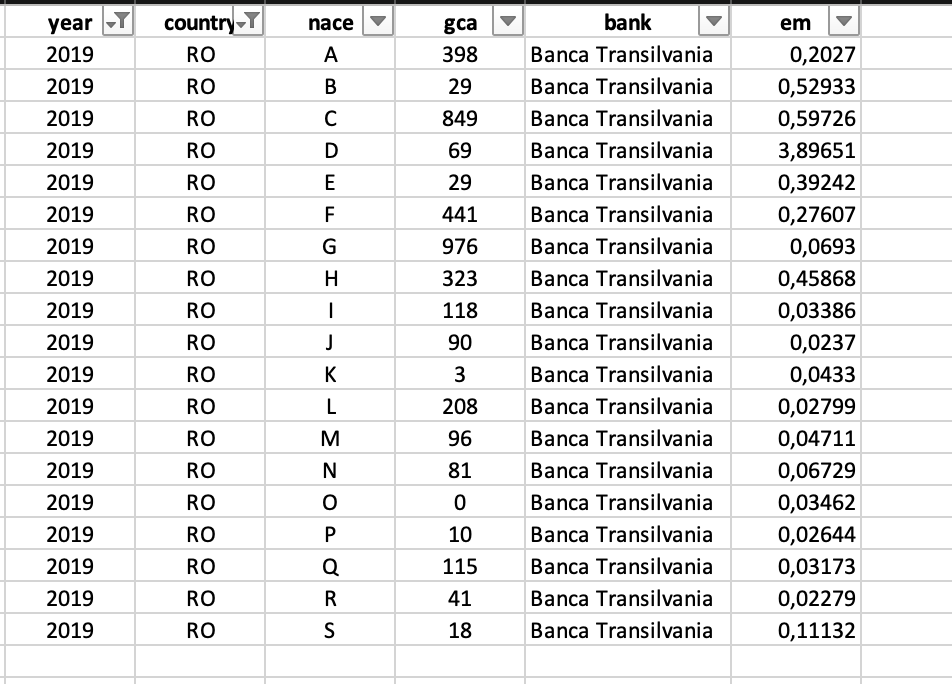 952×684 econometrics setting panel data set sample from economics.stackexchange.com
952×684 econometrics setting panel data set sample from economics.stackexchange.com  800×350 financial data monitor finance data concept analytics concept from www.dreamstime.com
800×350 financial data monitor finance data concept analytics concept from www.dreamstime.com  1600×1156 business finance data analysis chart financial management technology from www.dreamstime.com
1600×1156 business finance data analysis chart financial management technology from www.dreamstime.com  800×450 panel data data structure finance economics zulfiqar ali from medium.com
800×450 panel data data structure finance economics zulfiqar ali from medium.com  850×319 panel data analysis results financial depth spatial from www.researchgate.net
850×319 panel data analysis results financial depth spatial from www.researchgate.net  1470×980 spreadsheet table paper finance development banking account from www.vecteezy.com
1470×980 spreadsheet table paper finance development banking account from www.vecteezy.com  2559×1440 finance dashboards package from www.bizinfograph.com
2559×1440 finance dashboards package from www.bizinfograph.com  850×1134 panel data studies money demand findings table from www.researchgate.net
850×1134 panel data studies money demand findings table from www.researchgate.net  1200×1200 finance datasets complete singapore kaggle from www.kaggle.com
1200×1200 finance datasets complete singapore kaggle from www.kaggle.com  800×449 financial market screen business data ai generative stock from www.dreamstime.com
800×449 financial market screen business data ai generative stock from www.dreamstime.com  2055×1560 access critical financial data power applications from www.leantech.me
2055×1560 access critical financial data power applications from www.leantech.me  626×626 premium ai image financial data from www.freepik.com
626×626 premium ai image financial data from www.freepik.com  1536×977 financial data apis xsheets from www.10xsheets.com
1536×977 financial data apis xsheets from www.10xsheets.com  768×1024 spreadsheet financial data analysispen stock photo fmua from depositphotos.com
768×1024 spreadsheet financial data analysispen stock photo fmua from depositphotos.com  626×417 premium ai image financial report chart data analysis web from www.freepik.com
626×417 premium ai image financial report chart data analysis web from www.freepik.com  390×280 financial data analysis dashboard fintech stock photo from www.shutterstock.com
390×280 financial data analysis dashboard fintech stock photo from www.shutterstock.com